
Model Re-Adaptation Under Domain Shift
The Real Problem
Most vision models do not fail because their first training run was poor. They fail because the world changes after that run: new data sources, new imaging conditions, changed class balance, new product variants, new annotation practices, and gradual drift in what "normal" looks like.
For long-lived computer vision systems, the central question is therefore not just "How do I train this model?" but "How do I re-adapt this model repeatedly without losing prior capability?"
What I Studied Across Chapters 4 and 5
Two thesis chapters address this from complementary angles:
- Chapter 4 (Dual-Carriageway Framework): focused on fine-grained classification and compared different training pathways as new datasets become available over time.
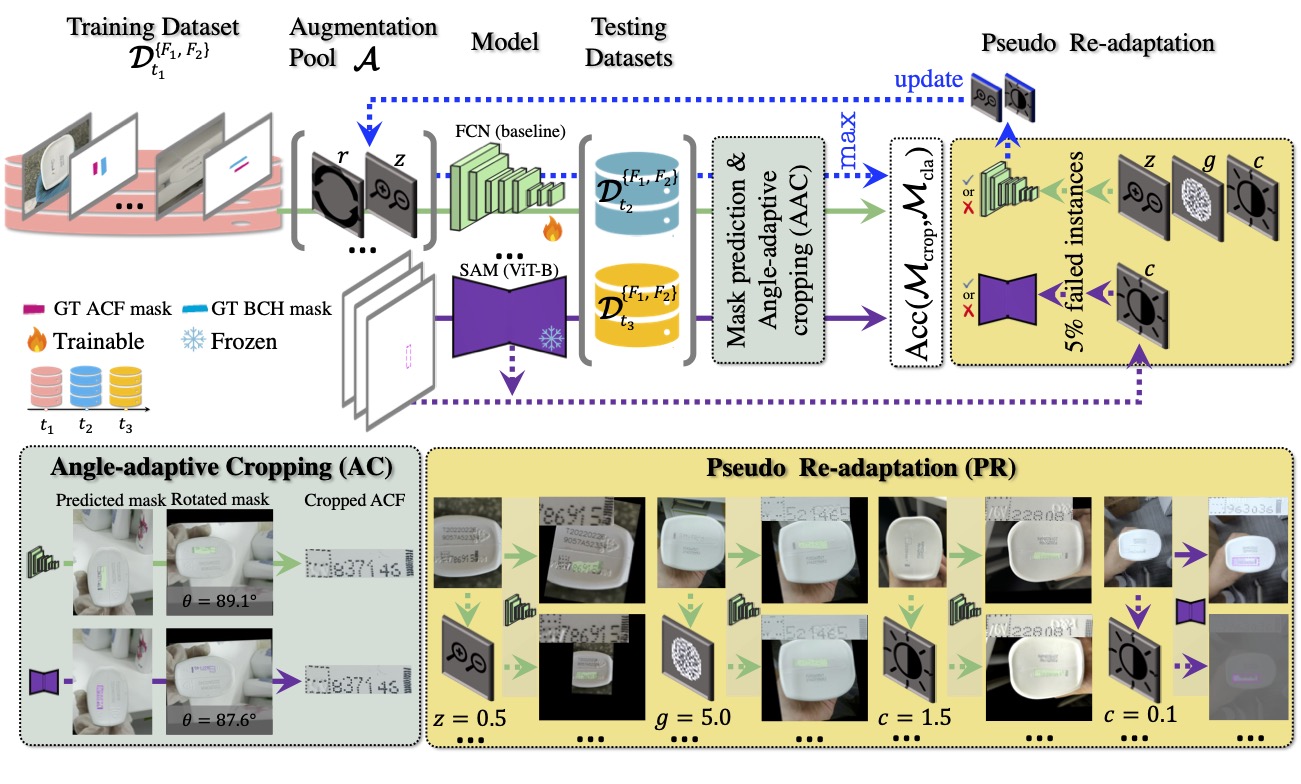
- Chapter 5 (Augmentation-based Model Re-adaptation Framework): focused on segmentation under temporal domain shift, using an evolving augmentation pool plus pseudo re-adaptation to maintain mask and downstream classification quality.
Classification Re-Adaptation: Stability vs Plasticity
In classification, I compared pathways such as retraining on combined historical+new data versus sequential fine-tuning. This exposes the classic trade-off:
- From-scratch mixed-data retraining usually gives better stability on old and new distributions, but has higher compute and retraining cost.
- Sequential fine-tuning adapts quickly and cheaply, but can degrade older classes if historical signal is not actively preserved.
In practice, this is not only a modelling decision; it is an operational decision tied to update cadence, compute budget, and tolerance for temporary regressions.
Padding and Input Conditioning Matter More Than Expected
An important finding from the Dual-Carriageway work is that "small" preprocessing choices can produce measurable differences in robustness and explainability. Padding scheme selection, for example, influenced confidence behaviour and transfer performance.
This reinforces a broader point: robust adaptation is often built from a stack of controlled low-level decisions, not from one dramatic algorithmic change.
Segmentation Re-Adaptation: Evolving Augmentation Pools
In segmentation, fixed augmentation recipes were often too static for evolving deployment conditions. The augmentation-based re-adaptation framework addressed this by incrementally extending the augmentation pool using observed failure patterns and curriculum-style pseudo re-adaptation.
The result was improved segmentation and crop reliability under later time-slice datasets, which then improved downstream classification quality as well.
Deployment Playbook for Re-Adaptation
A practical process that follows the thesis findings looks like this:
- Monitor drift indicators: track quality distribution, confidence shifts, and classwise error changes.
- Choose adaptation path per update: decide between full mixed retraining and staged fine-tuning using expected drift magnitude.
- Preserve historical competence: include replay or mixed historical data in adaptation loops to reduce forgetting risk.
- Maintain augmentation governance: add or tune augmentations based on concrete observed failures, not generic defaults.
- Validate on old and new splits: never evaluate only on latest data; adaptation must be judged on retention and acquisition together.
Why This Generalizes Beyond My Domain
Although these studies were motivated by an industrial visual inspection setting, the same pattern appears in many modern CV systems:
- medical imaging models updating across scanners and sites,
- retail/warehouse recognition models across seasons and devices,
- autonomy/perception stacks across weather and camera updates.
In all of these, the challenge is continuous adaptation under uncertainty, with hard constraints on reliability.
Related Papers and Thesis Source
- Zuo, Z., Smith, J., Stonehouse, J., Obara, B. (2024). Robust and Explainable Fine-Grained Visual Classification with Transfer Learning: A Dual-Carriageway Framework. CVPR Workshop 2024. [arXiv](https://arxiv.org/abs/2405.05853).
- Zuo, Z., Smith, J., Stonehouse, J., Obara, B. (2024). An Augmentation-based Model Re-adaptation Framework for Robust Image Segmentation. ECCV Workshops (Best Paper Award).
- PhD Thesis Chapters 4 and 5 (2025).
Related Posts
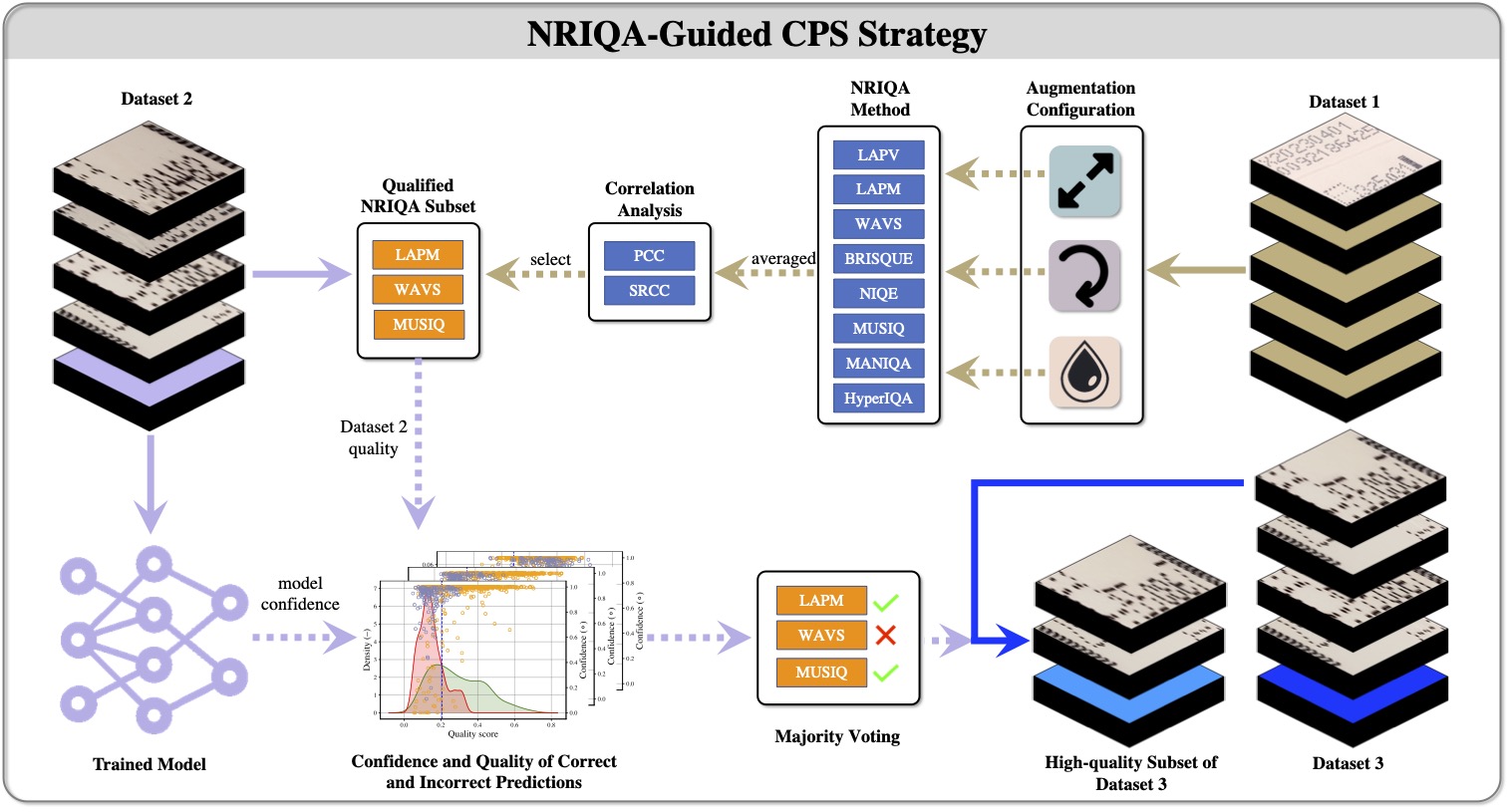
Image Quality Filtering for Fine-Grained Classification
This post covers why quality-aware training subset selection is often the first high-impact step before larger architecture changes.