
Image Quality Filtering for Fine-Grained Classification
Why This Problem Matters
Fine-grained visual classification (FGVC) is often presented as a model architecture problem: better backbones, better attention modules, better losses. In real deployment, however, one of the dominant failure drivers is much simpler: image quality mismatch between training and inference.
In industrial and mobile settings, images are captured under motion blur, inconsistent focus, variable illumination, compression artefacts, and changing devices. If training data contains too much low-information content, the model can learn brittle shortcuts or simply fail to learn stable class cues.
What I Investigated in Chapter 3
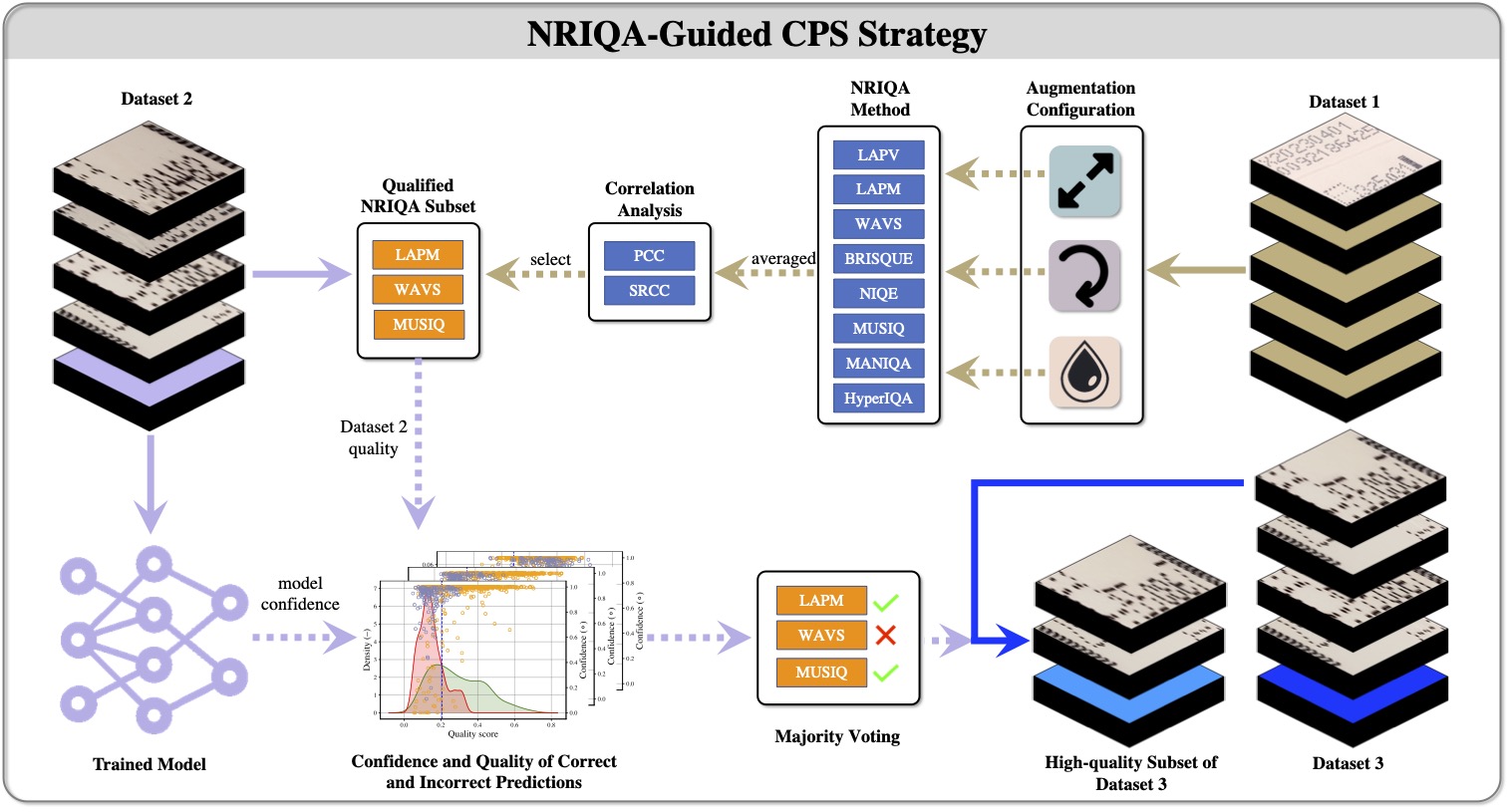
In Chapter 3 of my thesis (How Quality Affects Deep Neural Networks in Fine-Grained Image Classification), I evaluated whether no-reference image quality assessment (NRIQA) can be used as a practical data selection mechanism before training.
The core idea was to avoid a binary split of "perfect" versus "imperfect" images. Instead, I used quality scores plus confidence-quality analysis to identify and remove the most harmful quality tail while preserving enough variation for robust learning.
Method Summary
The procedure was based on three linked components:
- Quality scoring without reference images: multiple NRIQA methods were evaluated, including statistical and deep-learning-based quality estimators.
- Cut-off Point Selection (CPS): quality thresholds were selected from the interaction between quality distributions and prediction behaviour, rather than chosen arbitrarily.
- High-quality vs all-quality training comparison: the same model families were trained under controlled settings to isolate the quality filtering effect.
This makes the setup operationally useful: the method can be applied in data pipelines where no pristine reference image exists.
Key Results
The main result was consistent: quality-filtered training subsets improved classification performance relative to all-quality training. One representative outcome was ResNet-34 improving from 81.2% to 85.4% when trained on filtered high-quality data.
This is a 4.2-point absolute gain in a practical FGVC setting. In larger decision pipelines, even modest absolute gains can materially reduce false alarms or re-inspection workload.
What This Means for Deployment
There are several deployment-level lessons that generalize beyond this specific thesis domain:
- Do not assume more training data is always better. Adding low-quality data indiscriminately can dilute discriminative signal.
- Quality filtering should be calibrated, not aggressive by default. Keeping realistic variation is important; removing only the lowest-quality tail is often enough.
- Integrate quality checks early in MLOps. Quality scoring is cheap enough to place in data ingestion and curation loops.
- Track quality drift over time. If incoming quality distribution shifts, model reliability can degrade even when class distribution is unchanged.
Recommended Minimal Workflow
If you want a lightweight replication path in another CV project, this sequence usually works:
- Compute NRIQA scores on candidate training images.
- Train baseline on full data.
- Train one filtered model after removing only the lowest quality tail.
- Compare not only accuracy but error profile and confidence calibration.
- Choose the threshold that improves stability, not just peak score.
Related Papers and Thesis Source
- Smith, J., Zuo, Z., Stonehouse, J., Obara, B. (2024). How Quality Affects Deep Neural Networks in Fine-Grained Image Classification. VISAPP 2024. [arXiv](https://arxiv.org/abs/2405.05742).
- PhD Thesis Chapter 3 (2025): How Quality Affects Deep Neural Networks in Fine-Grained Image Classification.
Related Posts
Model Re-Adaptation Under Domain Shift
If you are applying quality filtering in production, this follow-up post covers how to keep models stable as incoming data changes over time.